Nesta página selecionamos os principais livros que descrevem especificamente sobre a plataforma de BI Open Source: Pentaho Business Intelligence. Também listamos livros que auxiliam no processo de conhecimento sobre conceitos relacionados a Business Intelligence independente da ferramenta.
Algumas Suites de BI proprietárias e livros genéricos possuem opções gratuitas para downloads, no qual podem ajudar no processo de aprendizado. Grande parte dessas informações foram utilizadas como base no desenvolvimento de nossos materiais didáticos nos Treinamentos em Pentaho Business Intelligence que oferecemos.
Para os iniciantes recomendamos nesse primeiro momento a leitura de livros conceituais, pois ainda não sabem exatamente os propósitos de uma solução de Business Intelligence. Após adquirir o conceito do BI sugerimos se aprofundar no aprendizado da Suite Pentaho.
O assunto dos livros foram organizados em níveis e sub níveis de categoria, sejam conceituais ou de softwares. A lista é constantemente atualizada pela equipe da Ambiente Livre, fazendo com que os consultores sempre utilizem as melhores praticas em seus projetos.
Livros Específicos Pentaho Business Intelligence
Plataforma Pentaho
Pentaho Solutions - Business Intelligence and Data Warehousing with Pentaho and MySQL
![]()
Este guia prático escrito por dois grandes participantes da comunidade Pentaho. O livro cobre todos os componentes do Pentaho BI Suite. Você aprenderá a instalar, usar e manter o Pentaho - e encontrará muitas discussões de fundo que o atualizarão completamente sobre os conceitos de BI e Pentaho.
Explica também como criar e carregar um data warehouse com o Pentaho Kettle para integração de dados / ETL, criar manualmente relatórios JFree (serviços de pentaho reporting) usando consultas SQL diretas, criar cubos Mondrian (serviços de análise Pentaho) e anexá-los ao navegador de cubos do Jpivot.
Linguagem: Inglês
Autores: Roland Bouman, Jos van Dongen
648 páginas - Agosto 2009
Editora: John Wiley Consumer
Pentaho na Prática: Segunda Edição
![]()
Este livro vai te ajudar a aprender a usar a Versão 4.8 da suite Pentaho para construir soluções de BI. É um livro principalmente técnico, mas você não precisa conhecer BI ou Pentaho para aproveitá-lo, pois ele avança paulatinamente, com minuciosas descrições.
A segunda edição traz o mesmo conteúdo da primeira, cobrindo a Suite Pentaho 4.8 (não inclui CTools), agora com uma editoração de qualidade superior, resultando em um livro de melhor qualidade.
Linguagem: Português
Autores: de Salles, Fábio, Moreno de Souza, Caio, Cesar Domingos
670 páginas - Julho 2016
Formato: eBook Kindle
Learning Pentaho CTools
![]()
Adquira sofisticação com os recursos do CTools e crie soluções de análise ricas e personalizadas usando o Pentaho.
Se você é um desenvolvedor do CTools e gostaria de expandir seu conhecimento em criar painéis interativos, estruturas atraentes e visualizações de dados que podem fazer a diferença, esse é o livro certo para você.
Linguagem: Inglês
Autores: Miguel Gaspar
367 páginas - Maio 2016
Editora: Packt Publishing
Kettle - Pentaho Data Integration
Pentaho Data Integration Cookbook - Second Edition
![]()
O Pentaho Data Integration Cookbook Second Edition é escrito em um formato de livro de receitas. Isso permite que você vá diretamente para o seu tópico de interesse ou siga os tópicos ao longo de um capítulo para obter um conhecimento profundo. O Cookbook de Integração Segunda Edição foi desenvolvido para desenvolvedores familiarizados com o básico do Kettle, mas que desejam avançar para o próximo nível. Também é voltado para usuários avançados que desejam aprender a usar os novos recursos do PDI, bem como práticas recomendadas para trabalhar com a Kettle.
Linguagem: Inglês
Autores: Alex Meadows, Adrián Sergio Pulvirenti, María Carina Roldán
411 páginas - Dezembro 2013
Editora: Packt Publishing
Pentaho Kettle Solutions- Building Open Source ETL Solutions with Pentaho Data Integration
![]()
Guia completo para instalação, configuração e gerenciamento de Pentaho Kettle. Se você é um administrador de banco de dados ou desenvolvedor, primeiro você terá noções básicas de Kettle e como aplica-lo para criar soluções ETL, depois avançar para os conceitos especializados, tais como clustering, extensibilidade e modelos de dados vault. Aprenda a projetar e construir todas as fases de uma solução de ETL.
Linguagem: Inglês
Autores: Matt Casters, Roland Bouman, Jos van Dongen
720 páginas - Setembro 2010
Editora: Wiley
Learning Pentaho Data Integration 8 CE
![]()
O Pentaho Data Integration (PDI) é um ambiente gráfico e intuitivo, com design de arrastar e soltar e poderosos recursos Extract-Tranform-Load (ETL). Este livro mostra e explica os novos recursos interativos do Spoon, a aparência renovada e os recursos mais recentes da ferramenta. Além disso você aprenderá no final do livro os principais pontos de como atender os requisitos de manipulação de dados.
Linguagem: Inglês
Autores: Maria Carina Roldan
500 páginas - Dezembro 2017
Editora: Packt Publishing
Pentaho Data Integration Quick Start Guide
![]()
O Pentaho Data Integration (PDI) é um ambiente intuitivo e gráfico, repleto de design de arrastar e soltar e poderosos recursos Extract-Transform-Load (ETL). Dado seu poder e flexibilidade, as tentativas iniciais de usar a ferramenta Pentaho Data Integration podem ser difíceis ou confusas. Este livro é a solução ideal.
Linguagem: Inglês
Autores: Maria Carina Roldan
178 páginas - Agosto 2018
Editora: Packt Publishing
Pentaho Data Integration Beginner's Guide, Second Edition
![]()
O livro mostra todos os aspectos do Pentaho Data Integration, fornecendo instruções sistemáticas em um estilo amigável, permitindo que você aprenda brincando com a ferramenta. Ao longo do livro são fornecidas inúmeras dicas e sugestões úteis para desenvolvedores de software, administradores de banco de dados, estudantes de TI e todos os envolvidos ou interessados no desenvolvimento de soluções ETL e/ou manipulação de dados.
Linguagem: Inglês
Autores: María Carina Roldán
502 páginas - Agosto 2013
Editora: Packt Publishing
Instant Pentaho Data Integration Kitchen
![]()
Um guia prático com dicas fáceis de seguir, ajudando os desenvolvedores a coletar dados de fontes diferentes, como bancos de dados, arquivos e aplicativos, transformar os dados em um formato unificado, acessível e relevante para os usuários finais. Você aprenderá como usar as ferramentas de linha de comando com eficiência ou para aprofundar alguns aspectos das ferramentas para ajudá-lo a trabalhar melhor.
Linguagem: Inglês
Autores: Sergio Ramazzina
59 páginas - Julho 2013
Editora: Packt Publishing
Pentaho Report Designer
Pentaho 5.0 Reporting by Example: Beginners Guide
![]()
Um tutorial prático, incluindo vários exemplos de gerenciamento de aplicativos usando o Citrix XenApp 6.5. O Citrix XenApp Performance Essentials é destinado a arquitetos de TI e administradores de sistemas que trabalham com o Citrix XenApp, onde é necessário um guia prático e ágil para ajustar e otimizar o desempenho.
Linguagem: Inglês
Autores: Mariano Garcia Mattio, Dario R. Bernabeu
212 páginas - Agosto 2013
Editora: Packt Publishing
Pentaho Reporting 3.5 for Java Developers
![]()
Você que precisa instalar uma solução de relatório em seu ambiente e deseja aprender conceitos avançados no Pentaho Reporting, como sub-relatórios, guias cruzadas, configuração da fonte de dados e relatórios baseados em metadados, este é seu livro.
Tutorial muito prático, repleto de exercícios e exemplos, apresenta uma variedade de conceitos no Pentaho Reporting. Com capturas de tela que mostram como os relatórios são exibidos no tempo de design e como devem ser renderizados em PDF, Excel ou HTML.
Linguagem: Inglês
Autores: Will Gorman
260 páginas - Setembro 2009
Editora: Packt Publishing
Pentaho 8 Reporting for Java Developers
![]()
Crie os melhores relatórios e resolva problemas comuns com o mínimo de esforço dominando os recursos básicos e avançados do Pentaho 8 Reporting.
Este tutorial prático, repleto de exercícios e exemplos, apresenta uma variedade de conceitos no Pentaho Reporting. Com capturas de tela que mostram como os relatórios são exibidos no tempo de design e como devem ser renderizados quando PDF, Excel, HTML, Texto, Arquivo Rich Text, XML e CSV.
Linguagem: Inglês
Autores: Francesco Corti
351 páginas - Setembro 2017
Editora: Packt Publishing
Pentaho Business Analytics
Pentaho Business Analytics Cookbook
![]()
Este guia prático contém uma ampla variedade de dicas, levando você a todos os tópicos necessários para se familiarizar rapidamente com o Pentaho e ampliar seu conjunto de habilidades Pentaho. Se você está envolvido em atividades diárias usando a plataforma Pentaho Business Analytics, este é o livro para você. É um bom companheiro para você se familiarizar rapidamente com tudo o que precisa para aumentar sua produtividade com a plataforma. Assumimos familiaridade básica com Pentaho, design de data warehouse e SQL, HTML e XML.
Linguagem: Inglês
Autores: Sergio Ramazzina
366 páginas - Junho 2014
Editora: Packt Publishing
Pentaho Analytics for MongoDB
![]()
Este é um guia fácil de seguir sobre os principais pontos de integração entre o Pentaho e o MongoDB. Empregando uma abordagem prática projetada para que o Pentaho seja configurado para conversar com o MongoDB desde o início, para que você obtenha resultados rápidos.
Este livro é destinado a analistas de negócios, arquitetos de dados e desenvolvedores novos no Pentaho ou no MongoDB que desejam oferecer uma solução completa para armazenamento, processamento e visualização de dados.
Linguagem: Inglês
Autores: Bo Borland
99 páginas - Fevereiro 2014
Editora: Packt Publishing
Pentaho Analytics for MongoDB Cookbook
![]()
Mais de 50 receitas para aprender a usar o Pentaho Analytics e o MongoDB para criar soluções poderosas de análise e relatório. Acelere o acesso a dados e maximize a produtividade com recursos exclusivos do Pentaho para MongoDB.
O livro ensinará como explorar e visualizar seus dados no Pentaho BI Server usando o Pentaho Analyzer, criar painéis avançados com seus dados além de guiar você pelo Pentaho Data Integration e saber como ele funciona com o MongoDB.
Linguagem: Inglês
Autores: Joel Latino, Harris Ward
131 páginas - Setembro 2016
Editora: Packt Publishing
Pentaho for Big Data Analytics
![]()
O livro é um guia prático, cheio de exemplos passo a passo fáceis de seguir e implementar. É destinado para desenvolvedores, administradores de sistema e profissionais de inteligência de negócios que desejam aprender como obter mais de seus dados através do Pentaho.
Linguagem: Inglês
Autores: Manoj R Patil, Feris Thia
70 páginas - Novembro 2013
Editora: Packt Publishing
Livros sobre Conceitos de Business Intelligence
Business Intelligence Guidebook from Data Integration to Analytics
![]()
Entre os conceitos de alto nível de inteligência de negócios e as instruções detalhadas para o uso das ferramentas dos fornecedores, encontra-se a camada essencial, ainda que pouco compreendida, da arquitetura, design e processo. Sem esse conhecimento, o Big Data é menosprezado - os projetos fracassam, estão atrasados e ultrapassam o orçamento.
Com as diretrizes práticas para a criação de soluções bem-sucedidas de BI, DW e integração de dados, você poderá projetar a arquitetura geral para os sistemas de inteligência de negócios em funcionamento com os aplicativos de armazenamento de dados e integração de dados.
Linguagem: Inglês
Autores: Rick Sherman
675 páginas - Novembro 2014
Editora: Elsevier Science
Successful Business Intelligence: Unlock the Value of BI & Big Data, Second Edition
![]()
Expandido para cobrir o que há de mais recente em inteligência de negócios - big data, nuvem, celular, descoberta de dados visuais e memória -, este best-seller totalmente atualizado pelo guru de BI Cindi Howson fornece as técnicas mais modernas para explorar o BI com o maior ROI.
O livro baseia-se em dados de pesquisas exclusivas e estudos de caso reais de histórias de sucesso de BI na Netflix, Medtronic, Macys.com, The Dow Chemical Company, Learning Circle e outras empresas para identificar as melhores práticas comprovadas de BI que podem ser usadas corretamente longe.
Este guia prático é a chave para reunir inovações tecnológicas com as pessoas, processos e cultura de qualquer organização, a fim de alcançar uma estratégia de BI competitiva e lucrativa.
Linguagem: Inglês
Autores: Cindi Howson
331 páginas - Outubro 2013
Editora: Mcgraw-hill
Star Schema The Complete Reference
![]()
Aprenda as melhores práticas de design dimensional. Esquema em estrela (Star Schema): a referência completa oferece uma cobertura detalhada dos princípios de design e seus fundamentos subjacentes. Organizado em torno dos conceitos de design e ilustrado com exemplos detalhados, este é um guia passo a passo para iniciantes e um recurso abrangente para especialistas.
Este volume começa com os fundamentos dimensionais do projeto e mostra como eles se encaixam em diversas arquiteturas de data warehouse, incluindo as de W.H. Inmon e Ralph Kimball. Através de uma série de técnicas avançadas que ajudam a lidar com a complexidade do mundo real, maximizar o desempenho e se adaptar aos requisitos dos produtos de software de BI e ETL.
Linguagem: Inglês
Autores: Christopher Adamson
653 páginas - Julho 2010
Editora: Mcgraw-hill
BI Como Deve Ser: O Guia Definitivo
![]()
A obra BI Como deve ser uma novidade no ramo de Business Intelligence , pois toda a discussão é centrada na explicação direta e objetiva de como os profissionais de tecnologia ou os negócios podem iniciar o projeto de BI do zero.
Diferenciação e linguagem clara, o livro BI Como Deve ser a busca por informação, como também por profissionais da área de negócios.
Linguagem: Português
Autores: Diego Elias Oliveira e Grimaldo Lopes de Oliveira
Acesse: https://www.bicomodeveser.com.br
Data Warehouse - Modelo Dimensional
The Data Warehouse Toolkit: The Complete Guide to Dimensional Modeling
![]()
Modelagem dimensional tornou-se a abordagem mais amplamente aceite para os projetos de data warehouses. Uma biblioteca completa com técnicas de modelagem dimensional - a mais completa coleção já escrita. Expandida para cobrir as técnicas básicas e avançadas para otimizar os dados do projeto do data warehouse, guia clássico de Ralph Kimball.
Linguagem: Inglês
Autor: Ralph Kimball, Margy Ross
464 páginas - Abril 2002
Editora: Wiley
Dimensional Modeling: In a Business Intelligence Environment
![]()
Nesta publicação Redbooks IBM são demonstradas técnicas de modelagem de dados dimensional e tecnologia, voltados especificamente para business intelligence e data warehousing. Ajudar o leitor a compreender como projetar, manter e utilizar um modelo dimensional para armazenamento de dados que podem fornecer o acesso a dados e desempenho necessários para inteligência de negócios.
Linguagem: Inglês
Autores: Chuck Ballard, Daniel M. Farrell, Amit Gupta, Carlos Mazuela, Carlos Mazuela
664 páginas - Março 2006 ( Atualizado maio 2008 )
Editora: Redbooks
Onde realizar Download: http://www.redbooks.ibm.com/abstracts/sg247138.html?Open
MDX - MultiDimensional eXpressions
MDX Solutions: With Microsoft SQL Server Analysis Services
![]()
Um tutorial prático sobre a construção e utilização de armazéns de dados multidimensionais. A linguagem de consulta SQL é usado para acessar dados em bancos de dados. Mas, para armazéns multidimensional (OLAP), a Microsoft desenvolveu MDX. A linguagem de consulta MDX se tornou essencial know-how para os desenvolvedores e usuários, seja para armazéns de dados ou para elaboração de orçamentos e sistemas de planejamento.
Linguagem: Inglês
Autor: George Spofford
416 páginas - Julho 2001
Editora: Wiley
InfoSphere Warehouse: Cubing Services and Client Access Interfaces
![]()
Este livro tem um excelente capítulo sobre MDX, os demais são aplicados a tecnologias IBM. InfoSphere Warehouse ™ .
Panorama com objetivo principal de discutir e descrever as capacidades de um determinado componente do InfoSphere Warehouse: InfoSphere Warehouse Cubing.
Linguagem: Inglês
Autores: Chuck Ballard, Deepak Rangarao, Jimmy Tang, Philip Wittann, Zach Zakharian, Andy Perkins, Robert Frankus
446 páginas - Dezembro 2008
Editora: Redbooks
Onde realizar Download: http://www.redbooks.ibm.com/abstracts/sg247582.html?Open
{loadposition sobre-ambientelivre-bi}


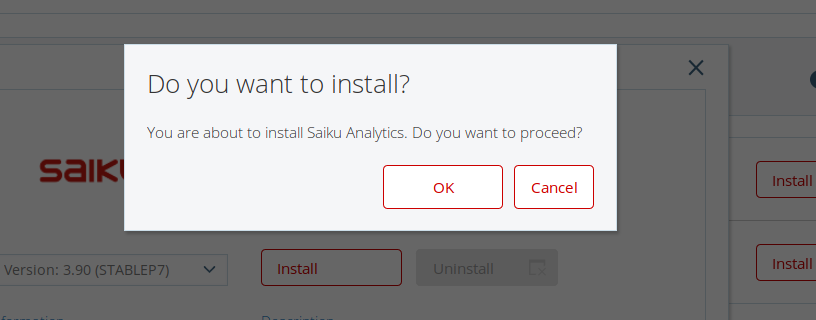
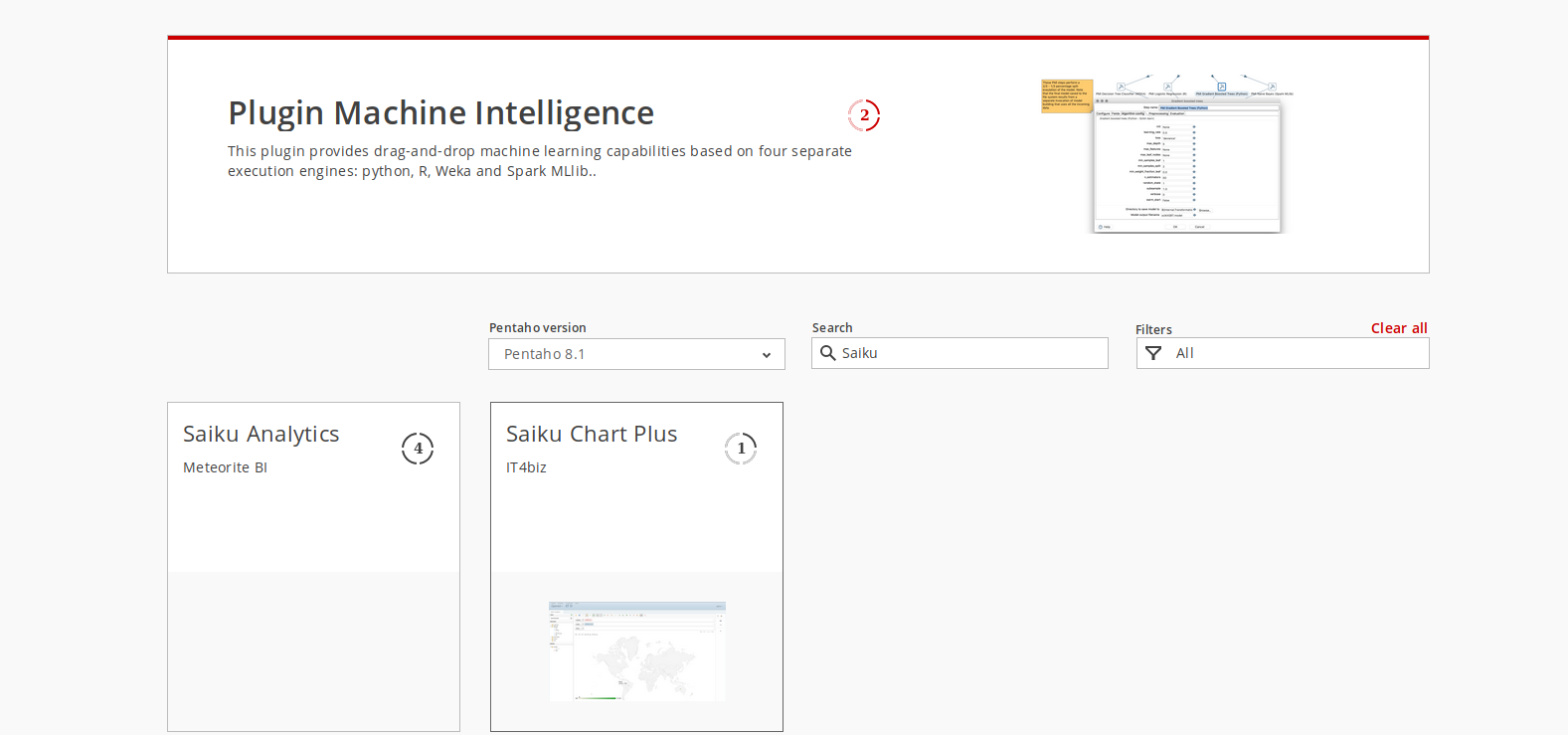
 Com o Pentaho podemos utilizar qualquer SGBD para armazenamento do nosso DatawareHouse ou Para extração de dados e apresentação de relatórios. Dois itens são importantes para conectar o Pentaho ao SGBD Oracle , primeiramente o Driver estar nos seus devidos locais de bibliotecas externas e a string de conexão estar configurada corretamente.
Com o Pentaho podemos utilizar qualquer SGBD para armazenamento do nosso DatawareHouse ou Para extração de dados e apresentação de relatórios. Dois itens são importantes para conectar o Pentaho ao SGBD Oracle , primeiramente o Driver estar nos seus devidos locais de bibliotecas externas e a string de conexão estar configurada corretamente.  O Saiku
O Saiku
 Servidor Web Java, especialista em aplicações J2EE, que é a tecnologia ao qual o Pentaho Bi Server foi desenvolvido, mais especificamente o tomcat é um contêiner de servlets. O Tomcat possui algumas características próprias de um servidor de aplicação, porém não pode ser considerado um servidor de aplicação por não preencher todos os requisitos necessários.
Servidor Web Java, especialista em aplicações J2EE, que é a tecnologia ao qual o Pentaho Bi Server foi desenvolvido, mais especificamente o tomcat é um contêiner de servlets. O Tomcat possui algumas características próprias de um servidor de aplicação, porém não pode ser considerado um servidor de aplicação por não preencher todos os requisitos necessários. O repositório de conteúdo Apache Jackrabbit ™ é uma implementação totalmente em conformidade do API de Repositório de Conteúdo para Java Technology (JCR, especificado em JSR 170 e JSR 283). Um repositório de conteúdo é um armazenamento hierárquico com suporte para conteúdo estruturado e não estruturado, pesquisa de texto completo, versão, transações, observação e muito mais.
O repositório de conteúdo Apache Jackrabbit ™ é uma implementação totalmente em conformidade do API de Repositório de Conteúdo para Java Technology (JCR, especificado em JSR 170 e JSR 283). Um repositório de conteúdo é um armazenamento hierárquico com suporte para conteúdo estruturado e não estruturado, pesquisa de texto completo, versão, transações, observação e muito mais. Spring Security é uma aplicação para controle de autenticação forte e altamente personalizável, possui quadro de controle nos acessos. É o padrão de fato para proteger aplicativos baseados em Spring. O mesmo se integra ao Tomcat e ao Pentaho BI Server para administração da segurança do servidor de aplicação.
Spring Security é uma aplicação para controle de autenticação forte e altamente personalizável, possui quadro de controle nos acessos. É o padrão de fato para proteger aplicativos baseados em Spring. O mesmo se integra ao Tomcat e ao Pentaho BI Server para administração da segurança do servidor de aplicação. O Hibernate é um framework para o mapeamento objeto relacional escrito na linguagem Java, mas também é disponível em .Net como o nome NHibernate. No pentaho ele e responsável pelo mapeamento das bases de dados para o data warehouse.
O Hibernate é um framework para o mapeamento objeto relacional escrito na linguagem Java, mas também é disponível em .Net como o nome NHibernate. No pentaho ele e responsável pelo mapeamento das bases de dados para o data warehouse. O Quartz é um agendador (scheduler) open source, serviço de agendamento de tarefas que podem ser integrados ou utilizados ao longo de praticamente qualquer Java EE ou aplicativo Java SE.
O Quartz é um agendador (scheduler) open source, serviço de agendamento de tarefas que podem ser integrados ou utilizados ao longo de praticamente qualquer Java EE ou aplicativo Java SE. O HSQLDB (do inglês Hyperthreaded Structured Query Language Database) é um servidor de banco de dados (SGBD), de código aberto, escrito totalmente na linguagem Java. Não é possível compará-lo, em termos de robustez e segurança com outros servidores SGBD, como Oracle ou Microsoft SQL Server, entretanto o HSQLDB é uma solução simples, que utiliza poucos recursos e que possui bom desempenho. Devido a essas características, ele é bastante utilizado em aplicações que são executadas em desktops e que necessitam interagir com uma camada de persistência através da linguagem SQL. A suíte office OpenOffice/ BrOffice, na sua versão 2.0, inclui o HSQLDB como engine de armazenamento de dados.
O HSQLDB (do inglês Hyperthreaded Structured Query Language Database) é um servidor de banco de dados (SGBD), de código aberto, escrito totalmente na linguagem Java. Não é possível compará-lo, em termos de robustez e segurança com outros servidores SGBD, como Oracle ou Microsoft SQL Server, entretanto o HSQLDB é uma solução simples, que utiliza poucos recursos e que possui bom desempenho. Devido a essas características, ele é bastante utilizado em aplicações que são executadas em desktops e que necessitam interagir com uma camada de persistência através da linguagem SQL. A suíte office OpenOffice/ BrOffice, na sua versão 2.0, inclui o HSQLDB como engine de armazenamento de dados.